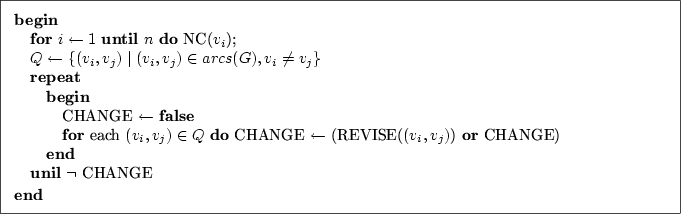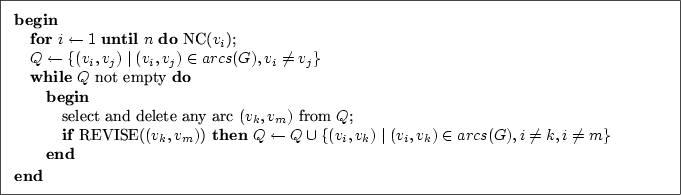Ein höherer, lokaler Konsistenzgrad ist die Kantenkonsistenz. Im Gegensatz zur Knotenkonsistenz bezieht sich die Kantenkonsistenz nicht auf die Wertebereiche einzelner Knoten im Constraint-Netz, sondern auf die Domänen der Knoten, die durch eine Kante verbunden sind, d.h. über ein Constraint zueinander in Relation stehen. Für gewöhnlich bezieht sich Kantenkonsistenz aus Gründen der Vereinfachung auf binäre Constraint-Netze.
Kantenkonsistenz stellt sicher, dass die Wertebereiche der Variablen auf die Werte beschränkt werden, die kompatibel zu unmittelbar benachbarten Variablen sind. Zu jedem möglichen Wert einer Variable muss ein passender Wert in den Wertebereichen der Variablen vorhanden sein, die zu dieser Variable über ein Constraint in Relation stehen.5.15 Formal lässt sich dies wie folgt ausdrücken (vgl. Güsgen, 2000, S. 270):
Ein Constraint-Netz ist kantenkonsistent, wenn alle Constraints kantenkonsistent sind. Erreicht wird dies, indem Änderungen der Wertebereiche der Constraint-Variablen mittels entsprechender Algorithmen durch das Netz propagiert werden. Alleine durch Herstellung der Kantenkonsistenz kann im Regelfall allerdings keine eindeutige Lösung für ein CSP bestimmt werden, bzw. lässt sich nicht eindeutig feststellen, dass es keine Lösung gibt.
In Abbildung 5.3 ist die zur Erzeugung von
Kantenkonsistenz notwendige Propagation anhand des
Constraint-Beispiels aus
Abschnitt 3.6.3 f. dargestellt. In (a)
wird während eines Konfigurierungsvorgangs die Taktfrequenz des
Prozessors P_FSB_Rate mit 100 festgelegt. Die Auswertung
der Kante bzw. des Constraints ![]() bewirkt, dass der Wertebereich
von MB_FSB_Rate ebenfalls auf den Wert 100 eingeschränkt
wird (b). Die Auswertung des Constraint
bewirkt, dass der Wertebereich
von MB_FSB_Rate ebenfalls auf den Wert 100 eingeschränkt
wird (b). Die Auswertung des Constraint ![]() in (c) schränkt
wiederum den Wertebereich von S_FSB_Rate ein. In (d) ist
zu sehen, wie durch Auswertung von
in (c) schränkt
wiederum den Wertebereich von S_FSB_Rate ein. In (d) ist
zu sehen, wie durch Auswertung von ![]() sichergestellt wird, dass die
Wertebereiche von P_FSB_Rate und S_FSB_Rate
konsistent mit
sichergestellt wird, dass die
Wertebereiche von P_FSB_Rate und S_FSB_Rate
konsistent mit ![]() sind. Da dies der Fall ist, sind keine weiteren
Wertebereichseinschränkungen erforderlich. Das Ergebnis der
Propagation ist ein kantenkonsistentes Constraint-Netz, welches noch
keine eindeutige, allerdings zwei potentielle Lösungen bietet.
sind. Da dies der Fall ist, sind keine weiteren
Wertebereichseinschränkungen erforderlich. Das Ergebnis der
Propagation ist ein kantenkonsistentes Constraint-Netz, welches noch
keine eindeutige, allerdings zwei potentielle Lösungen bietet.
Im Folgenden werden einige einfache Algorithmen von
Mackworth (1977a) vorgestellt, mit deren Hilfe
Kantenkonsistenz erzeugt werden kann. Der in
Abbildung 5.4 dargestellte Algorithmus
REVISE kann dazu genutzt werden, in
knotenkonsistenten, binären Constraint-Netzen zwischen
den übergebenen Variablenpaaren
![]() Kantenkonsistenz herzustellen. Erreicht wird dies, indem der
Algorithmus sämtliche möglichen Werte
Kantenkonsistenz herzustellen. Erreicht wird dies, indem der
Algorithmus sämtliche möglichen Werte ![]() der ersten
Variable daraufhin untersucht, ob es für jeden Wert einen kompatiblen
Wert in der Domäne
der ersten
Variable daraufhin untersucht, ob es für jeden Wert einen kompatiblen
Wert in der Domäne ![]() der zweiten Variable gibt. Wenn dies nicht
der Fall ist, kann der Wert
der zweiten Variable gibt. Wenn dies nicht
der Fall ist, kann der Wert ![]() aus der Domäne
aus der Domäne ![]() gelöscht
werden.5.16 Der Algorithmus
REVISE muss auf alle Kanten bzw. binären Constraints
angewendet werden. Da er nicht symmetrisch ist, müssen neben den
Variablenpaaren
gelöscht
werden.5.16 Der Algorithmus
REVISE muss auf alle Kanten bzw. binären Constraints
angewendet werden. Da er nicht symmetrisch ist, müssen neben den
Variablenpaaren ![]() ebenfalls die entsprechenden Paare
ebenfalls die entsprechenden Paare
![]() geprüft werden.
geprüft werden.
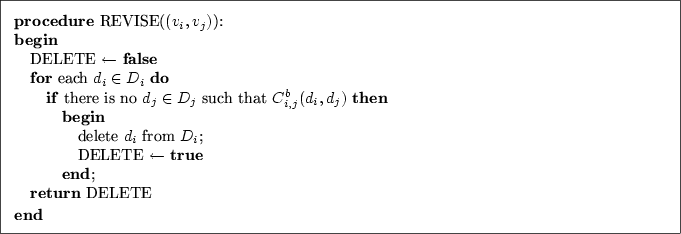 |
Nachdem der Algorithmus auf ein Paar ![]() angewendet wurde, ist
dieses Variablenpaar zwar kantenkonsistent, bleibt dies aber u.U.
nicht. Wenn die Variable
angewendet wurde, ist
dieses Variablenpaar zwar kantenkonsistent, bleibt dies aber u.U.
nicht. Wenn die Variable ![]() ebenfalls zu anderen Variablen durch
binäre Constraints in Relation steht, löscht der Algorithmus
voraussichtlich aus der Domäne von
ebenfalls zu anderen Variablen durch
binäre Constraints in Relation steht, löscht der Algorithmus
voraussichtlich aus der Domäne von ![]() ebenfalls Werte, so dass
anschließend wiederum der Wertebereich von
ebenfalls Werte, so dass
anschließend wiederum der Wertebereich von ![]() überprüft werden
muss, um Kantenkonsistenz zu gewährleisten.
Ein einfacher Durchlauf von
REVISE ist demnach nicht ausreichend. Stattdessen muss der
Algorithmus solange aufgerufen werden, bis keine Änderungen an den
Domänen mehr vorgenommen wurden. Erst danach ist die Kantenkonsistenz
des Constraint-Netzes sichergestellt. Ein Algorithmus, der diese
Funktion übernimmt, ist der in Abbildung 5.5
dargestellte, einfachste Kantenkonsistenz-Algorithmus
AC-1. Der Algorithmus
AC-1 arbeitet allerdings nicht sehr effizient,
da alle Variablenpaare erneut untersucht werden müssen, solange bei
einem Durchlauf auch nur eine einzige Änderung an der Domäne einer
Variable vorgenommen wurde.
überprüft werden
muss, um Kantenkonsistenz zu gewährleisten.
Ein einfacher Durchlauf von
REVISE ist demnach nicht ausreichend. Stattdessen muss der
Algorithmus solange aufgerufen werden, bis keine Änderungen an den
Domänen mehr vorgenommen wurden. Erst danach ist die Kantenkonsistenz
des Constraint-Netzes sichergestellt. Ein Algorithmus, der diese
Funktion übernimmt, ist der in Abbildung 5.5
dargestellte, einfachste Kantenkonsistenz-Algorithmus
AC-1. Der Algorithmus
AC-1 arbeitet allerdings nicht sehr effizient,
da alle Variablenpaare erneut untersucht werden müssen, solange bei
einem Durchlauf auch nur eine einzige Änderung an der Domäne einer
Variable vorgenommen wurde.
Eine Verbesserung ist der Algorithmus AC-2
(vgl. Mackworth, 1977a, S. 106), der dem von
Waltz (1975) beschriebenen
Filteralgorithmus entspricht.
AC-2 erreicht Kantenkonsistenz mit nur einem
einzigen Durchgang der äußeren Schleife durch die Knoten, benötigt
dafür allerdings neben Q eine zweite dynamische Liste ![]() .
Aufgrund der Eigenschaften des Algorithmus AC-2
kann es bei Zyklen > 2 im Constraint-Netz dazu kommen, dass eine
Kante in beiden Listen Q und
.
Aufgrund der Eigenschaften des Algorithmus AC-2
kann es bei Zyklen > 2 im Constraint-Netz dazu kommen, dass eine
Kante in beiden Listen Q und ![]() gleichzeitig auf
Bearbeitung wartet (vgl. Mackworth, 1977a, S. 107). Dies
unterschiedet den Algorithmus von dessen Nachfolger
AC-3. Der
AC-3-Algorithmus (siehe
Abbildung 5.6) ist eine Vereinfachung bzw. Verallgemeinerung von AC-2. Er ist nicht mehr
darauf ausgelegt, Kantenkonsistenz mit einem einzigen Durchlauf
herzustellen. Es wird lediglich eine einzige dynamische Liste
Q verwaltet, die wie in AC-1 alle
Kanten des Constraint-Netzes enthält.5.17 Bei
Reduzierung des Wertebereichs von
gleichzeitig auf
Bearbeitung wartet (vgl. Mackworth, 1977a, S. 107). Dies
unterschiedet den Algorithmus von dessen Nachfolger
AC-3. Der
AC-3-Algorithmus (siehe
Abbildung 5.6) ist eine Vereinfachung bzw. Verallgemeinerung von AC-2. Er ist nicht mehr
darauf ausgelegt, Kantenkonsistenz mit einem einzigen Durchlauf
herzustellen. Es wird lediglich eine einzige dynamische Liste
Q verwaltet, die wie in AC-1 alle
Kanten des Constraint-Netzes enthält.5.17 Bei
Reduzierung des Wertebereichs von ![]() durch REVISE müssen
alle davon betroffenen Kanten
durch REVISE müssen
alle davon betroffenen Kanten ![]() an die Liste Q
angefügt werden.5.18 Dies wird solange
wiederholt, bis keine Reduzierung der Wertebereiche mehr erfolgt und
die Liste Q vollständig abgearbeitet wurde.
an die Liste Q
angefügt werden.5.18 Dies wird solange
wiederholt, bis keine Reduzierung der Wertebereiche mehr erfolgt und
die Liste Q vollständig abgearbeitet wurde.
Auch der AC-3-Algorithmus ist noch keineswegs optimal. So werden auch durch diesen Algorithmus bei weiteren Durchläufen mit REVISE noch häufig Wertepaare geprüft, von denen bereits bekannt ist, dass sie kompatibel miteinander sind. Eine Reihe von Algorithmen befasst sich damit, diese Metainformationen zu verwalten und durch weniger Konsistenztests effizientere Laufzeiten zu erreichen (siehe Tabelle 5.1). Der AC-4-Algorithmus von Roger Mohr und Thomas C. Henderson nutzt intern eine separate Datenstruktur zur extensionalen Constraint-Repräsentation (vgl. Mohr und Henderson, 1986). Dadurch wird es möglich, REVISE nur für Wertepaare auszuführen, die von einer vorherigen Wertebereichseinschränkung betroffen sind: Ein Wert in einer Domäne gilt als supported, wenn für diesen Wert konsistente Wertebelegungen für alle übrigen Variablen existieren. Wenn in einer Domäne ein Wert gelöscht wird, müssen nicht mehr alle Werte in den Domänen der mit dieser Variablen über ein Constraint verbundenen Variablen getestet werden, sondern nur noch die Werte, die auf den gelöschten Wert über einen support-Eintrag angewiesen waren.
Während also AC-3 bereits nur noch Wertepaare von Kanten prüft, die von Änderungen betroffen sind, reduziert AC-4 nochmals die zu überprüfenden Wertepaare auf diejenigen, die direkt von einer Änderung betroffen sind. Dies resultiert in einer optimalen worst-case Zeitkomplexität, da nicht mehr Konsistenztests als notwendig vorgenommen werden. Allerdings wird diese Verbesserung mit stark erhöhter Platzkomplexität und einer im Durchschnitt dicht am worst-case befindlichen Zeitkomplexität erkauft, so dass der AC-3-Algorithmus in der Praxis häufig performanter als AC-4 arbeitet, trotzdem er das schlechtere worst-case Laufzeitverhalten aufweist vgl. Bessière, 1994a, S. 180; Bessière und Cordier, 1993, S. 108; Wallace, 1993, S. 239 ff..5.19 Insbesondere in Anwendungen, in denen die Domänen der Constraint-Variablen sehr viele Werte aufweisen, ist aufgrund der erhöhten Platzkomplexität von AC-4 der AC-3-Algorithmus vorzuziehen.
AC-3 und AC-4 gehören zu bisher den am weitesten verbreiteten Algorithmen zur Herstellung von Kantenkonsistenz. Es gibt noch eine Reihe weiterer Algorithmen, die allerdings in der Praxis bisher keine so große Verbreitung gefunden haben. So ist der AC-5-Algorithmus von Pascal Van Hentenryck et al. ein genereller Algorithmus, der sich auf andere Kantenkonsistenz-Algorithmen reduzieren lässt (vgl. Van Hentenryck et al., 1992). AC-3 und AC-4 können als Spezialisierungen von AC-5 gesehen werden. AC-5 besitzt eine besondere Bedeutung für CLP-Sprachen, da sich spezielle, hier vorkommende Klassen von Constraints mittels weiterer Spezialisierungen von AC-5 auf besonders effiziente Weise verarbeiten lassen. AC-5* ist eine Verbesserung von AC-5 in der Hinsicht, dass sich Spezialisierungen nicht nur bzgl. der Zeitkomplexität sondern auch bezogen auf die Platzkomplexität optimieren lassen (vgl. Liu, 1996).
Eine Verbesserung von AC-4 ist der AC-6-Algorithmus von Christian Bessière und Marie-Odile Cordier. AC-6 besitzt bei verringerter Platzkomplexität dasselbe worst-case Laufzeitverhalten wie AC-4 und arbeitet in der Praxis schneller als AC-3 und AC-4. Der AC-6-Algorithmus berechnet für jeden Wert einer Variable zunächst lediglich eine konsistente Wertebelegung pro Constraint. Weitere konsistente Belegungen (bzw. supports) werden erst bei Bedarf erzeugt, d.h. wenn eine vorherige Belegung inkonsistent geworden ist. Die Technik von AC-6 wird deshalb auch lazy oder minimal support genannt (vgl. Bessière und Cordier, 1993; Bessière, 1994a). Weitere Verbesserungen bringt die Berücksichtigung von zusätzlichem Wissen über Constraints, wie die Auswertung von Symmetrieeigenschaften, welches in die Erweiterungen AC-6+ (vgl. Bessière, 1994b) bzw. AC-6++ (vgl. Bessière und Régin, 1995) eingeflossen ist. Die Bemühungen weitere Metainformationen zu berücksichtigen mündeten durch die Arbeiten von von Christian Bessière, Eugene C. Freuder und Jean-Charles Régin in dem Algorithmus AC-7, der bei gleicher Zeit- und Platzkomplexität wie AC-6 durch geschicktes Ausnutzen der Bidirektionalität von Constraints5.20 weitere Werteüberprüfungen vermeidet (vgl. Bessière et al., 1995,1999a).5.21
Weil die Datenstrukturen von AC-4,
AC-6 und AC-7 zur
Vermeidung von doppelten Konsistenztests sehr komplex sind und der
Verwaltungsaufwand die Effizienz der Algorithmen in der Praxis
vermindert, wurde versucht den Algorithmus AC-3
ohne zusätzliche Datenstrukturen zu verbessern.
AC-8 (vgl. Chmeiss und Jégou, 1998,1996b), AC-![]() (vgl. van Dongen, 2002b,a) und
AC-2000
(vgl. Bessière und
Régin, 2001b,a) sind überarbeitete und leicht verbesserte
Versionen von AC-3, die wie der originale
Algorithmus ohne aufwendige Datenstrukturen auskommen. Bei gleicher
worst-case Komplexität wie AC-3
vermindern sie in der Praxis die Anzahl der benötigten
Konsistenztests.5.22
AC-3.1 (vgl. Zhang und Yap, 2001) und
AC-2001
(vgl. Bessière und
Régin, 2001b,a) sind Verbesserungen von
AC-3, die durch ähnliche Techniken mit sehr
einfachen zusätzlichen Datenstrukturen wesentliche Verbesserungen
erreichen. AC-3.1 und
AC-2001 sind optimale Algorithmen, d.h. sie besitzen eine optimale worst-case Zeitkomplexität, bei
gleicher Platzkomplexität wie AC-6 und
AC-7.
(vgl. van Dongen, 2002b,a) und
AC-2000
(vgl. Bessière und
Régin, 2001b,a) sind überarbeitete und leicht verbesserte
Versionen von AC-3, die wie der originale
Algorithmus ohne aufwendige Datenstrukturen auskommen. Bei gleicher
worst-case Komplexität wie AC-3
vermindern sie in der Praxis die Anzahl der benötigten
Konsistenztests.5.22
AC-3.1 (vgl. Zhang und Yap, 2001) und
AC-2001
(vgl. Bessière und
Régin, 2001b,a) sind Verbesserungen von
AC-3, die durch ähnliche Techniken mit sehr
einfachen zusätzlichen Datenstrukturen wesentliche Verbesserungen
erreichen. AC-3.1 und
AC-2001 sind optimale Algorithmen, d.h. sie besitzen eine optimale worst-case Zeitkomplexität, bei
gleicher Platzkomplexität wie AC-6 und
AC-7.
Die Komplexität von Kantenkonsistenz-Algorithmen ist für den worst-case für binäre Constraints aus theoretischen Gründen auf quadratische Größenordnungen begrenzt. Auch zukünftige Algorithmen können daran nichts ändern. Da mit zunehmendem Grad lokaler Konsistenz, die Komplexität exponentiell anwächst, wird häufig vermieden, einen Konsistenzgrad größer als den der Kantenkonsistenz herzustellen. Ein weiterer Konsistenzgrad allerdings, der für bestimmte Anwendungen eine wichtige Rolle spielt, ist die Pfadkonsistenz.
![\begin{figure}\centering
\includegraphics[width=\linewidth]{images/constraints_ac}
\ifx\pdfoutput\undefined
\fi
\end{figure}](img121.png)